
Introduction
What is CDK
If you already know what CDK is, feel free to skip this section.
The AWS Cloud Development Kit (CDK in short) is a relatively new framework for defining cloud Infrastructure as Code (IaC).
CDK offers a high-level object-oriented abstraction to define AWS resources imperatively using the power of modern programming languages. CDK addresses the same type of problems that tools like Terraform or CloudFormation aim to solve. What’s different with CDK is that you don’t have to write any JSON, YAML or HCL configuration files, but you can use your favorite programming language (right now TypeScript, Python, Java, C#/.Net and Go are supported).
CDK allows to easily define your cloud infrastructure by importing classes (resources) and instantiating objects. The resulting definition can be versioned in GIT, easily shared and used in command-line tools (for example in CI/CD pipelines). The underlying concept is that you can mutate your infrastructure through code, the same way you mutate any other application.
To give you an example, this is how you can create a new SQS queue and subscribe it to a new SNS topic using TypeScript:
import * as sqs from '@aws-cdk/aws-sqs';
import * as sns from '@aws-cdk/aws-sns';
export class HelloCdkStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const queue = new sqs.Queue(this, 'HelloCdkQueue', {
visibilityTimeout: cdk.Duration.seconds(300)
});
const topic = new sns.Topic(this, 'HelloCdkTopic');
topic.addSubscription(new subs.SqsSubscription(queue));
}
}By using CDK you can fully leverage the ecosystem of your favorite programming language. This means that you can use your favorite code editor and get all the niceties such as syntax highlighting, type checking and auto-completion. Also with CDK, your infrastructure can be as testable as any other code you write.
It’s worth knowing that CDK is actually an abstraction built on top of CloudFormation. So when you compile a CDK stack (the correct terminology is synthesize), you actually get a CloudFormation stack. And when you run cdk deploy you are actually deploying that stack with CloudFormation. This means that all the benefits of using Cloud Formation are directly inherited by CDK.
If you want to know how to get started with CDK, check out the official documentation Getting started with the AWS CDK.
What is Fargate
Warning: I am assuming you are already familiar with containers and Docker. If not, perhaps is a good idea to read more about the subject before diving into this post.
Before talking about Fargate, we first have to introduce what Amazon Elastic Container Service (Amazon ECS) is.
ECS is a highly scalable, high-performance container orchestration service that supports Docker containers and allows you to easily run and scale containerized applications on AWS.
Amazon ECS eliminates the need for you to install and operate your own container orchestration software, manage and scale a cluster of virtual machines, or schedule containers on those virtual machines.
Amazon ECS has two key launch type options available:
- EC2 ― deploy and manage your own cluster of EC2 instances for running the containers
- Fargate ― run containers directly, without any EC2 instances (serverless)
EC2 launch type allows you to have server-level, more granular control over the infrastructure that runs your container applications. With EC2 launch type, you can use Amazon ECS to manage a cluster of servers and schedule placement of containers on the servers. Amazon ECS keeps track of all the CPU, memory and other resources in your cluster, and also finds the best server for a container to run on based on your specified resource requirements. However you are entirely responsible for provisioning, patching, and scaling clusters of servers.
With Fargate on the other hand, all you have to do is package your application in containers, specify the CPU and memory requirements, define networking and IAM policies, and launch the application. In this sense, AWS Fargate is an entirely serverless, pay-as-you-go compute engine.
Terminology
Before going forward with the post we need to cover some of the ECS terminology first:
- Task ― this is the lowest building block of ECS. It can be thought as the smallest deployable unit in ECS. Each task is an instance of a Task Definition within a Cluster.
- Task Definition ― is a blueprint (expressed in JSON format in a text file) that describes one or more containers, up to a maximum of ten, that form your application. It contains settings like exposed ports, Docker images, CPU shares, memory requirements, data volumes, startup commands and environmental variables.
- Service ― defines long running tasks of the same Task Definition. This can be 1 running container or multiple running containers all using the same Task Definition. If any of your tasks should fail or stop for any reason, the Amazon ECS service scheduler launches another instance of your task definition to replace it and maintain the desired count of tasks in the service depending on the scheduling strategy used.
- Cluster ― a logic group of tasks or services. If you are running tasks or services that use the EC2 launch type, a cluster is also a grouping of container instances.
- Container Instance ― in the context of EC2 launch type, this is just an EC2 instance that is part of an ECS Cluster and has Docker and the
ecs-agentrunning on it.
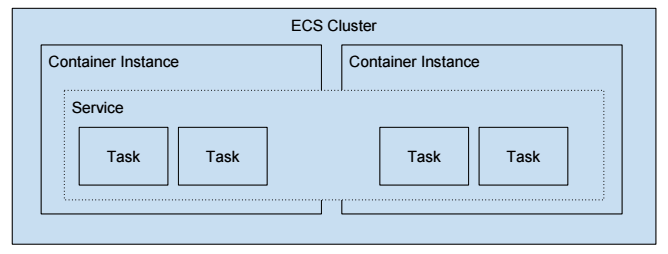
For example, the following image shows 4 running Tasks as part of an ECS Service. The Service and Tasks span 2 Container Instances. The Container Instances are part of a logical group called an ECS Cluster.
Enough with the theory. Let’s dive into my particular use case that made me think about using Fargate in the first place.
The Code
I needed to run a periodic task to perform a basic ETL (Extract Transform Load) process on a MySQL database.
The details of this task are irrelevant to this post. Let’s just say that the application that runs the business logic is written in Node.js, which means that the smallest deployable unit is composed by at least two containers: one running the MySQL instance and the other one running the Node.js application.
For this particular case, AWS Fargate is the perfect fit. Instead of paying (and maintaining) for an EC2 instance, and having to start and stop it between uses we can just ask AWS Fargate to run the containers when we need to, and stop paying when the container stops.
Ok let’s see how we can express all those concepts using the CDK. I’m going to use TypeScript, but the same concepts are valid in any other supported programming language.
The first step is to create a stack.
An AWS CDK app defines one or more stacks. Stacks (equivalent to AWS CloudFormation stacks) are collection of resources provisioned together as a single deployment unit. They contain constructs, each of which defines one or more concrete AWS resources, such as Amazon S3 buckets, Lambda functions, Amazon DynamoDB tables, and so on.
Here’s how a stack can be expressed in CDK:
import * as cdk from '@aws-cdk/core';
export class CdkFargateWorkloadStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
}
}Cluster
First of all we need to define the infrastructure required to run the task. We need to create the higher level construct, which in the context of ECS is a Cluster.
import * as ec2 from '@aws-cdk/aws-ec2';
import * as ecs from '@aws-cdk/aws-ecs';
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
declare const vpc: ec2.Vpc;
const cluster = new ecs.Cluster(this, 'Cluster', {
vpc,
});
}Clusters are region-specific, therefore you can decide the characteristics of the VPC that will host it. If you don’t, CDK will create a default VPC.
Task Definition
Next we can define our task definition. As we said, a task definition has one or more containers; typically, it has one main container (the default container is the first one that’s added to the task definition, and it is marked essential) and optionally some supporting containers.
To run a task or service with AWS Fargate tasks/services, we can use the FargateTaskDefinition construct. For this definition, the only required parameters are memory and CPU.
const taskDef = new ecs.FargateTaskDefinition(this, 'TaskDef', {
memoryLimitMiB: 2048,
cpu: 1024,
ephemeralStorageGiB: 50,
executionRole: this.createTaskExecutionRole()
});By default, Amazon ECS tasks hosted on Fargate using platform version 1.4.0 or later receive a minimum of 20 GiB of ephemeral storage. The total amount of ephemeral storage can be increased, up to a maximum of 200 GiB, by specifying the ephemeralStorage parameter in the task definition. In this case, for example, we’re allocating 50 Gib.
We’re also using a separate function to provide a value for the executionRole parameter.
There are two essential IAM roles that you need to understand to work with AWS ECS:
- task execution role ― is a general role that grants permissions to start the containers defined in a task. Those permissions are granted to the ECS agent so it can call AWS APIs on your behalf.
- task role ― grants permissions to the actual application once the containers are started.
import * as iam from '@aws-cdk/aws-iam';
private createTaskExecutionRole(): iam.Role {
const role = new iam.Role(this, 'TaskExecutionRole', {
assumedBy: new iam.ServicePrincipal('ecs-tasks.amazonaws.com'),
});
role.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AmazonECSTaskExecutionRolePolicy'));
return role;
}As you can see, the AmazonECSTaskExecutionRolePolicy gets attached to this role. This AWS policy grants permissions to:
- pull the container image from Amazon ECR,
- manage the logs for the task, i.e. to create a new CloudWatch log stream within a specified log group, and to push container logs to this stream during the task run.
Additionally, if you use any secrets (for example from AWS Systems Manager Parameter Store or AWS Secrets Manager) in your task definition, you need to attach another policy to the task execution role in order to let the ECS Agent pull those secrets.
Since our workload needs to be able to store data in a persistent storage, we need to let the task role to access a S3 bucket using the grantReadWrite method.
import * as s3 from '@aws-cdk/aws-s3';
const targetBucket = s3.Bucket.fromBucketName(this, 'TargetBucket', 'my-bucket');
targetBucket.grantReadWrite(taskDef.taskRole);Containers
To add containers to a task definition, we can use the addContainer() method:
import * as ecr from '@aws-cdk/aws-ecr';
// reference the ECR Repository
const repository = ecr.Repository.fromRepositoryName(this, 'AppRepository', 'my-application');
taskDef.addContainer('AppContainer', {
containerName: 'app',
image: ecs.ContainerImage.fromEcrRepository(repository),
essential: true,
environment: {
DB_HOST: '127.0.0.1',
DB_PORT: '3306',
DB_DATABASE: 'my_database',
DB_USERNAME: 'password'
},
secrets: {
// Retrieved from AWS Secrets Manager or AWS Systems Manager Parameter Store at container start-up.
// SECRET: ecs.Secret.fromSecretsManager(secret),
// DB_PASSWORD: ecs.Secret.fromSecretsManager(dbSecret, 'password'), // Reference a specific JSON field, (requires platform version 1.4.0 or later for Fargate tasks)
// PARAMETER: ecs.Secret.fromSsmParameter(parameter),
},
});
taskDef.addContainer('MysqlContainer', {
containerName: 'mysql',
// Use an image from DockerHub
image: ecs.ContainerImage.fromRegistry('bitnami/mysql:5.7.21'),
essential: true,
environment: {
ALLOW_EMPTY_PASSWORD: 'yes',
MYSQL_DATABASE: 'my_database'
}
});Or application code is packed in a Docker image and stored on AWS ECR. Creating an image and uploading on ECR is outside of the scope of this article. Check the Getting started if you don’t know where to begin.
Our AppContainer uses the Docker image stored in the my-application ECR repository. The ecs.ContainerImage.fromEcrRepository(repository) instruction always references the latest tagged image, but of course you can reference a specific tag.
On the other hand, images in the Docker Hub registry are available by default and can be referenced using the ecs.ContainerImage.fromRegistry instruction.
Both containers are marked as essential. This means that if the container fails or stops for any reason, all other containers that are part of the task are stopped. We could have omitted this flag because a container is assumed to be essential by default.
Finally the environment section lists the environment variables to pass to the container which will be used by the application. In this particular case we’re not really interested in hiding the value of DB_PASSWORD because the workload does not deal with sensitive information. However in most of the cases you should hide passwords and secret parameters. That’s why CDK lets you reference AWS Secrets Manager or AWS Systems Manager Parameter Store values to pass to the container before the startup process, using the secrets property.
Keep in mind that environment variable are always exposed during the CDK synthesize step (which can run on your local host or in the CI/CD pipeline), therefore they can potentially appear in logs. Instead, secrets values are retrieved only before the container startup process.
Service
Finally, we have to instruct ECS about the strategy that we intend to use for our containers. ECS provides different scheduling strategies, including running tasks on a cron-like schedule which is exactly what we want.
In CDK we can express this requirement by using the ecs-patterns module. This library provides higher-level Amazon ECS constructs which follow common architectural patterns. Those patterns are expressed through CDK L3 constructors. You can read more about them here.
The ScheduledFargateTask construct works perfectly for our requirements. We define our workload to run in the cluster defined previously and we instruct ECS to keep only one instance of the task definition alive.
Finally we can define the rule that will trigger our workload on an automated schedule in CloudWatch Events. All scheduled events use UTC time zone and the minimum precision for schedules is 1 minute.
import * as patterns from '@aws-cdk/aws-ecs-patterns';
const scheduledFargateTask = new patterns.ScheduledFargateTask(this, 'ScheduledFargateTask', {
cluster,
desiredTaskCount: 1,
scheduledFargateTaskDefinitionOptions: {
taskDefinition: taskDef
},
schedule: events.Schedule.cron({
day: '1',
hour: '4',
minute: '0'
})
});In this case we’re planning to run the workload every first day of the month, at 4 am.
Conclusions
That’s it. In this article we learned how to use CDK to provision a scheduled workload on AWS Fargate.
We also learned a bunch of related concepts such as:
- what is CDK
- what is Fargate
- what is ECS and its terminology
See you in the next post!